新卒で入った会社でマーケティングリサーチの部署にいて、日々ログデータなどなどの数値をSQL描いて抽出して、お絵描きしています。元気です。最近は、アンケートのデータもいじったりしています。そんな業務の中で名前を知って、何やお前ってなった概念NPSについての数理的(面積を求める程度)な理解をしたので、備忘録がてら説明しようかなと思いました。そんなわけで書いていきます。 書ききれていませんが。
NPSとは
NPSとは、「Net Promoter Score(ネットプロモータスコア)」の略称です。この指標を用いると、顧客ロイヤリティが測れる指標だそうです。すごいですね。
この指標は、なんか知らんけど顧客と企業との間の愛着や信頼が表現できて凄いらしいです。あと、企業の業績上昇と関連があるそうです。凄いですね。この指標のすごいところの説明についての詳細は、NTTコムオンラインの資料を参照してください。なんか凄いそうです。
NPSの計測方法
このNPSを計測するには、顧客に対して「あなたはこの企業(製品/サービス/ブランド)を友人や同僚に薦める可能性は、どのくらいありますか?」と質問して、『0(全くそう思わない)~ 5(どちらでもない) ~ 10(非常にそう思う)』の11段階で回答してもらうのだそうです。簡単ですね。
NPSでは、以上の質問の回答について、0点~6点の回答者に「批判者」、7 ~ 8点の回答者に「中立者」9 ~ 10 点の回答者に「推奨者」というラベルを貼ります。そして、全ての回答者に占める推奨者の割合から批判者の割合を引いたものをNPSスコアと呼ぶのだそうです。
補足として、上の計算方法で書いた割合はパーセンテージで表現した0~100の値を利用します。だから、全員推奨者の場合の 100 % - 0 % = 100 % の100から、全批判者の場合の 0% - 100 % = - 100 % の-100というスコアの間を取るのだそうです。ビジネスの場ではパーセントが好かれているんですね。
ただし、今回の記事では、パーセントで表現すると若干めんどくさいので、その割合を0以上1以下の少数で表すことにします。なので、本記事でのNPSは -1 ~ 1 の値を取ります。ビジネスライクな表現で理解したい人は、100掛けといてください。
さて、上に書いた計測方法を見たときの最初に抱いた僕の感想を箇条書きにしておきます。
11件法。。。無理矢理分散作ろうとしてる心理学の卒論みたいやな
平均値と中央値と分散の代表値でよくないか
ん?このNPSって、代表値みたいなもんと捉えて良いんか
多分みんな似たような感覚を持つでしょう。特に生データじっくり見る系の人は。んで、多分この指標の価値や意味が全くわからなくなるでしょうね。実際僕も業務でNPS実際に出すまでこの指標の価値がわかりませんでした。
仮想アンケートデータでNPSというものの振る舞いをチェック
##おまじない
rm(list = ls())
library(tidyverse)
library(DT)
library(SimMultiCorrData)
## macユーザーの皆様に向けて
set.seed(2525)ここからは乱数生成で模擬的なアンケート回答データを作成して、そのデータを見ながらNPSという指標の意味について解説していきます。
ここからは、乱数さん11000人をお呼びして彼らが回答してくれたアンケートデータを作ります。今回のアンケートデータでは、生データとして、company_id 、answer 、の列を用意します。それぞれ、アンケートの実施会についてのid、実際に得られたアンケート結果とします。
これから作るデータについて表にしてまとめておきます。
| company_id | 分布 | 与えるパラメータ |
|---|---|---|
| A社 | 一様分布 | ビヨーン。平均5 |
| B社 | 正規分布 | 平均値5、SD1 |
| C社 | 高得点者が多い分布 | 平均5、SD1、歪度-0.8(分布を右寄りに) |
| D社 | 低得点者が多い分布 | 平均5、SD1、歪度 .08(分布を左寄りに) |
| E社 | 二山分布(双峰分布) | 平均5、SD1、歪度-0.8の乱数さん5500人と平均5、SD1、歪度0.8の乱数さん5500人をくっつけ |
シミュレーション時のパラメータ付与
sample_size <- 11000
mean <- 5
sd <- 1.5
skew <- 0.8乱数さんご回答ありがとうございます
DF_a <- data.frame(
company_id = "A",
answer = floor( ## 0から11の一様乱数生成して、最後に小数点以下を切り捨て。
runif(sample_size, min=0, max=10+1)
)
)
DF_b <- data.frame(
company_id = "B",
answer = floor( ## 0から11の正規乱数生成して最後に小数点以下を切り捨て。
truncnorm::rtruncnorm(n = sample_size, a = 0, b = 10+1, mean = mean + 0.5, sd = sd) ## 小数点以下の切り捨ての関係で、0〜11の範囲で乱数作ってるので、その中心の5.5をmeanに設定。
)
)
c <- nonnormvar1( ##歪度0.5尖度0平均5.5の乱数生成。リストが出来上がる。
method = "Fleishman",
skews = - skew,
skurts = 0,
n = sample_size,
mean = mean + 0.5,
vars = sd^2
)
DF_c <- data.frame(
company_id = "C",
answer = floor(
c[["continuous_variable"]]$V1
)
)
d <- nonnormvar1( ##歪度0.5尖度0平均5.5の乱数生成。リストが出来上がる。
method = "Fleishman",
skews = skew,
skurts = 0,
n = sample_size,
mean = mean + 0.5,
vars = sd^2
)
DF_d <- data.frame(
company_id = "D",
answer = floor(
d[["continuous_variable"]]$V1
)
)
f <- nonnormvar1( ##歪度0.5尖度0平均5.5の乱数生成。リストが出来上がる。
method = "Fleishman",
skews = skew,
skurts = 0,
n = sample_size / 2,
mean = mean + 0.5 - 3,
vars = sd^2
)
f <- f[["continuous_variable"]]$V1
g <- nonnormvar1( ##歪度0.5尖度0平均5.5の乱数生成。リストが出来上がる。
method = "Fleishman",
skews = - skew,
skurts = 0,
n = sample_size / 2,
mean = mean + 0.5 + 3,
vars = sd^2
)
g <- g[["continuous_variable"]]$V1
e <- c(f,g)
DF_e <- data.frame(
company_id = "E",
answer = floor(e)
)
DF <- rbind(DF_a, DF_b, DF_c, DF_d, DF_e)
DF <- DF %>% mutate(
.,
NPS_label = case_when(
answer >= 9 ~ "promoter",
answer <= 6 ~ "detractor",
answer <= 8 ~ "passive"
)
)シミュレーションされたデータを確認
変なデータないかチェック
シミュレーションされたA社~E社についてそれぞれの記述統計量を確認してみます。
まずは、想定外の値を出していないかの確認。
tapply(DF$answer, DF$company_id, min) ## 最小値確認## A B C D E
## 0 0 0 3 0tapply(DF$answer, DF$company_id, max) ## 最大値確認## A B C D E
## 10 10 7 10 10table(DF$company_id)##
## A B C D E
## 11000 11000 11000 11000 11000質問紙の想定してる範囲からはみ出してる回答者はどの会社にもいませんね。あと、その想定してる範囲の回答者が設定した11000人いましたね。よかった。
次は平均値の確認。
tapply(DF$answer, DF$company_id, mean) ## 平均値算出## A B C D E
## 4.927455 4.999636 5.021909 4.975455 5.003273まあ当然と言えば当然ですが、平均値については、想定した5という得点にまとまりました。
次に標準偏差SDについては、
tapply(DF$answer, DF$company_id, sd) ## SD算出## A B C D E
## 3.170061 1.514965 1.554353 1.557965 3.399270乱数生成の際にパラメータとしてSD = sd(分散 = 1.5 ^ 2)を与えたB,C,D社については1.5になってくれました。ただし、パラメータを与えなかった一様分布のA社と二山分布のE社のそれは1.5になっていません。まあ当然のことですね。
まあ変なデータはなさそうですね。よかったよかった。
ヒストグラム(確率密度関数の分布)を見てみよう
簡単に出せてありがとう、ggplot2様。
DF %>% ggplot(
.,
aes(x = answer, color = company_id)
) + geom_density(
adjust = 2
) + xlim(-3, 13) 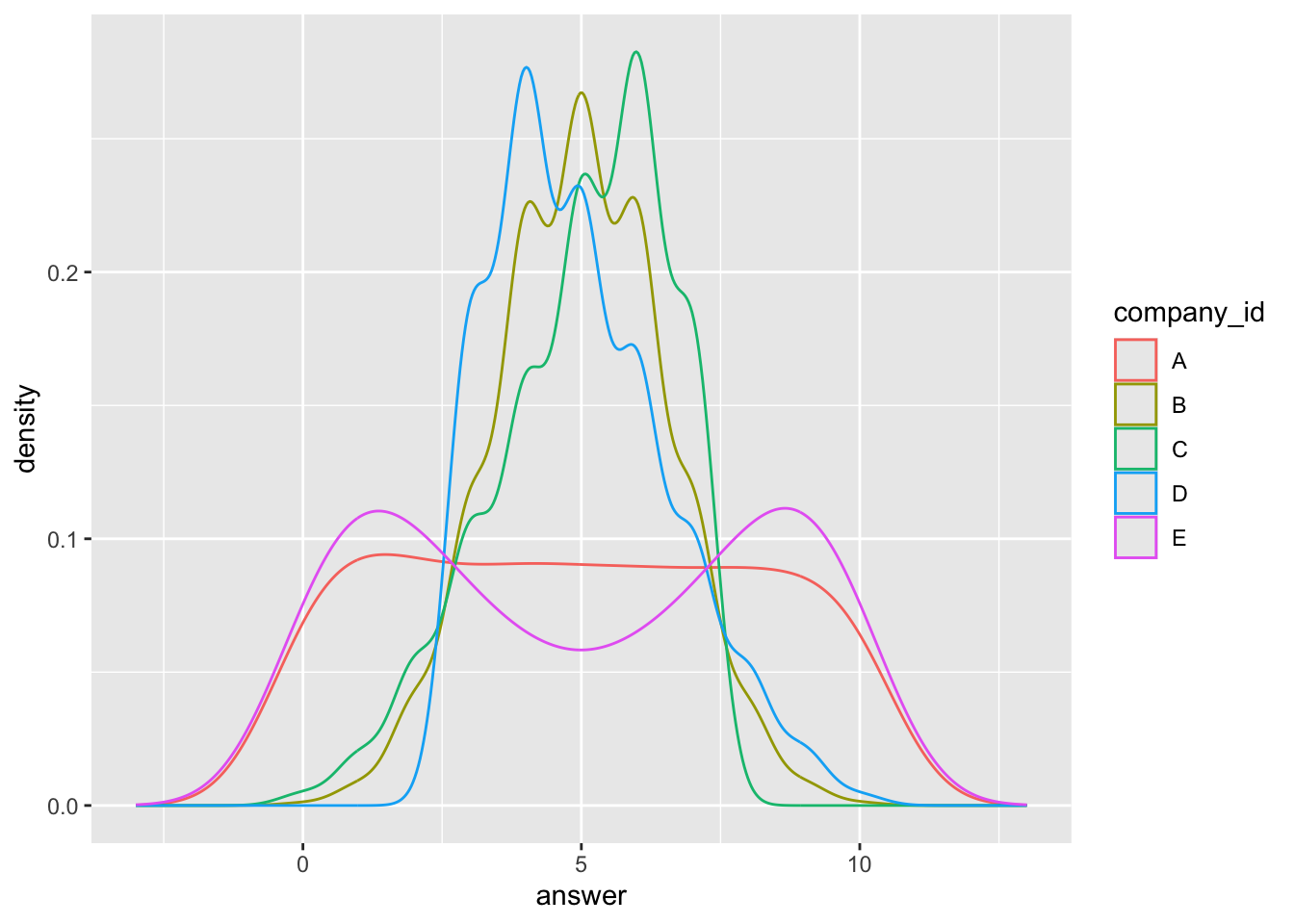
一応補足ですが、本来はデータは0~10敷かないのですが、確率密度の分布を滑らかにしているので、0未満10より大きいx軸も含められちゃってます。ヒストグラムも書いとくので、あんまりお気になさらず。
DF %>% ggplot(
.,
aes(x = answer, fill = company_id)
) + geom_histogram(
position = "identity",
alpha = 0.8
) + xlim(-3, 13) ## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 10 rows containing missing values or values outside the scale range
## (`geom_bar()`).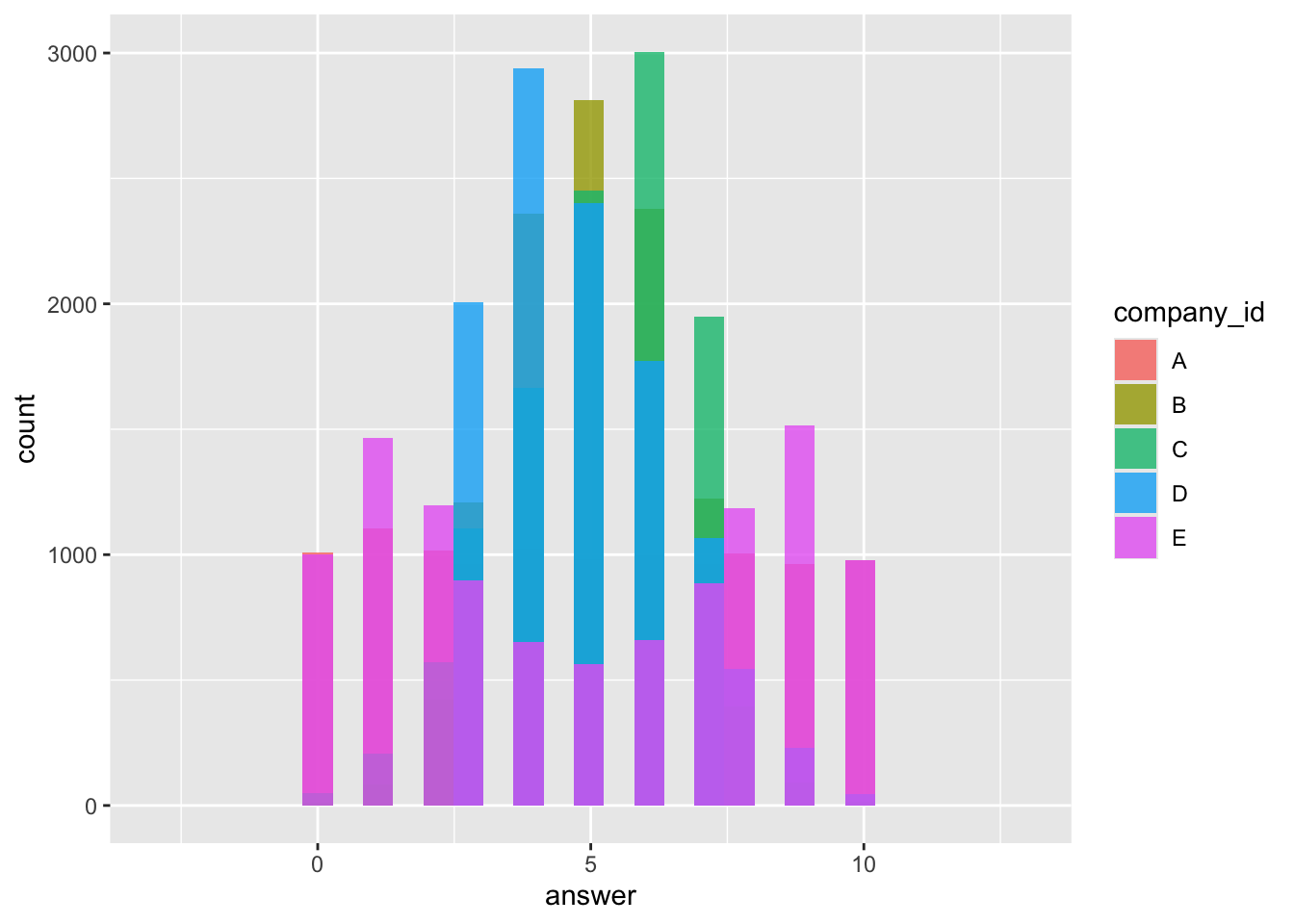
さて、最後に、NPSをそれぞれの会社で出してみましょう。
NPSの出し方は、(0~6の回答をした人の人数 - 9と10の回答をした人の人数 ) / その会社のアンケートの回答者数 なので、それを計算しましょう
## その範囲に回答者がいなかった場合、tidyverse::coutでは0が入らないため、チェック用に全会社idを取り出す。
company_ids <- DF %>% distinct(., company_id) %>% unlist()
## 批判者(detoractor)の数を数える。
detractor_num <- DF %>% group_by(
.,
company_id
) %>% count(
.,
answer <= 6
) %>% filter(
.,
`answer <= 6` == TRUE
) %>% mutate(
.,
n = n /sample_size
) %>% select(
.,
company_id, n
)
add_detractor_num <- data.frame(
company_id = company_ids[!company_ids %in% detractor_num$company_id],
n = ifelse(
is_empty(company_ids[!company_ids %in% detractor_num$company_id]), list(NULL),
0
)
)
detractor_num <- rbind(detractor_num ,add_detractor_num)
detractor_num <- detractor_num %>% arrange(
.,
company_id
)
## 推奨者(detoractor)の数を数える。
promoter_num <- DF %>% group_by(
.,
company_id
) %>% count(
.,
answer >= 9
) %>% filter(
.,
`answer >= 9` == TRUE
) %>% mutate(
.,
n = n /sample_size
) %>% select(
.,
company_id, n
)
add_promoter_num <- data.frame(
company_id = company_ids[!company_ids %in% promoter_num$company_id],
n = ifelse(
is_empty(company_ids[!company_ids %in% promoter_num$company_id]), list(NULL),
0
)
)
promoter_num <- rbind(promoter_num, add_promoter_num)
promoter_num <- promoter_num %>% arrange(
.,
company_id
)
DF_nps <- full_join(promoter_num, detractor_num, by = "company_id")
colnames(DF_nps) <- c("company_id", "promoter_ratio", "detractor_ratio")
DF_nps <- DF_nps %>% mutate(
.,
nps_score = promoter_ratio - detractor_ratio
)